
VoIP infrastructure evolved fast. Networks scaled, codecs multiplied, cloud deployments went from experimental to standard, and the number of network elements a single call traverses grew considerably. Monitoring practices at many organizations moved more slowly. Five patterns tend to surface when the tools and methods haven’t kept up with the infrastructure they’re supposed to cover.
Sign #1: Your Dashboard Goes Green the Moment a Call Connects
SIP signaling tells you whether a call was established. It records setup time, post-dial delay, and hang-up cause, giving operations teams a clear view of call connectivity across the network. For years, a clean SIP handshake served as the primary evidence that a voice service was performing well.
The problem with that assumption shows up in the RTP layer.
Once SIP sets up the call, and later tears it down cleanly, audio travels via the Real-time Transport Protocol across the IP network in a stream of 20-millisecond packets. Each packet takes its own route, competes with other traffic, and arrives subject to whatever conditions exist between the two endpoints at that moment.
This is where the two protocols part ways in terms of sensitivity. A SIP packet arriving 60ms late is a non-issue, the session will set up just fine. The same delay in an RTP stream translates directly into an audible gap. SIP can tolerate network hiccups; RTP simply can’t.
A call can produce a textbook SIP trace and still leave both parties listening to silence, one-sided audio, or speech that cuts out partway through a sentence.
When monitoring covers only the control plane, operations teams work with a fraction of the data a call actually generates. RTP media streams account for the overwhelming majority of VoIP traffic volume, yet plenty of monitoring setups track SIP alone.
The result is a dashboard that goes green at call setup, with no record of what happened during the conversation itself.
Correlating SIP and RTP data tells a different story. Monitoring can confirm the quality a call delivered, identify where packets dropped, flag audio degradation mid-call, and trace the problem back to a specific network element. Call connectivity is where every analysis starts, and RTP media is where it gets specific enough to actually act on.
Sign #2: Your Quality Metric Is a Single MOS Score Per Call
Mean opinion score has been the default call quality metric for decades, and the concept is sound: translate the listener’s experience into a number on a scale of one to five. The trouble isn’t MOS itself. It’s what happens when one averaged value gets applied to the entire duration of a call.
MOS started as a genuinely subjective measure. Groups of listeners rated audio samples, and averaging their scores produced a reference value. Modern systems calculate MOS algorithmically, estimating what a listener would score based on network measurements like packet loss, jitter, and latency.
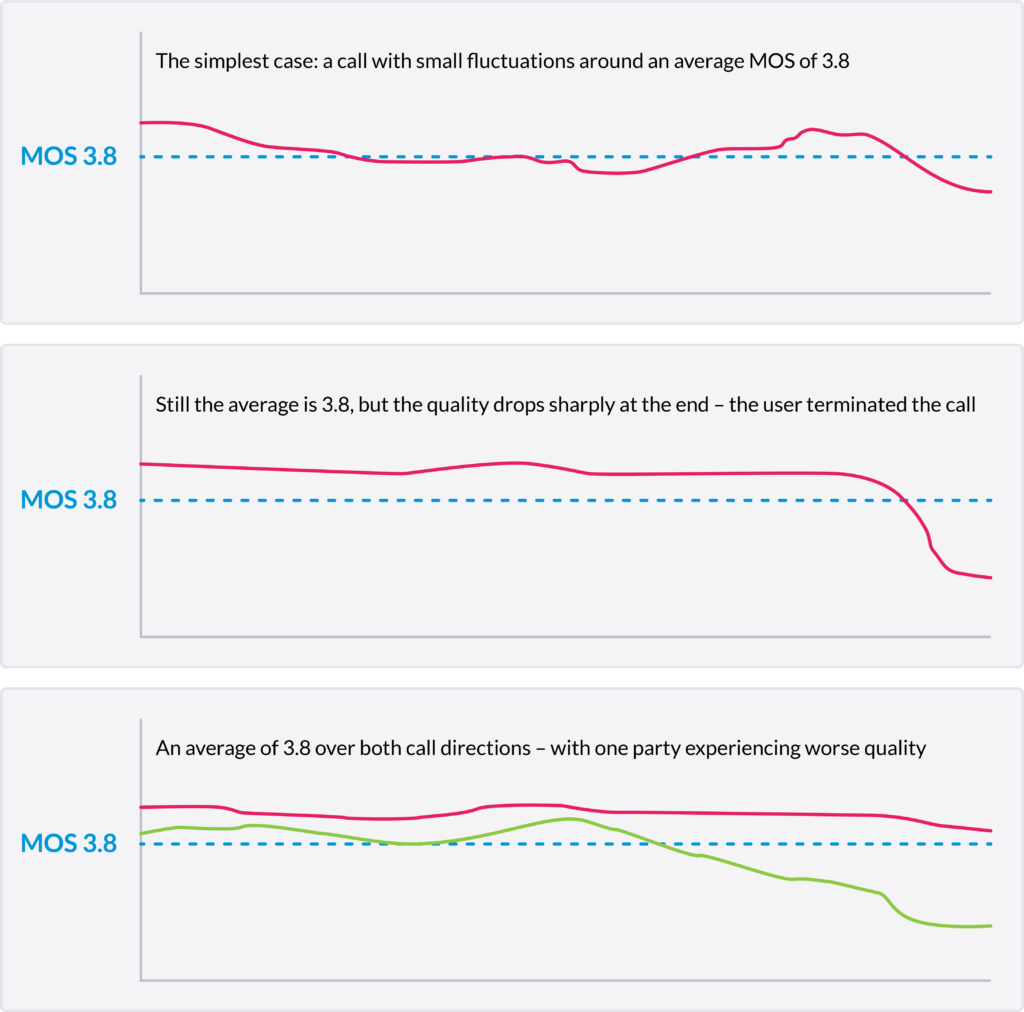
Averaged over a full call, the number obscures a lot.
Picture a ten-minute call where audio quality holds steady for the first nine minutes, then collapses sharply at the end, causing the caller to hang up. The average MOS for the full call stays relatively high, because the brief deterioration at the end pulls down a long stretch of clean audio only slightly. The score looks acceptable. The user’s experience was not.
A second scenario: two parties on the same call, one experiencing consistent audio quality, the other getting choppy, broken speech throughout. A single averaged MOS value for the call splits the difference between them. Neither experience shows up accurately.
Monitoring that samples quality throughout the call rather than averaging it after the fact catches both scenarios. Breaking each RTP stream into short, fixed-length intervals and calculating MOS for each segment separately produces a sequence of quality data records with genuine temporal resolution. ETSI TR 103 639 provides the standards framework for exactly this kind of timeslice-based analysis.
With that granularity, a sharp quality drop at minute nine really shows up as a sharp drop. A one-sided quality problem shows up in the affected stream. Operations teams stop working from summary scores and start working from the actual shape of what happened.
Sign #3: Your Monitoring System’s First Alert Is a Customer Complaint
Most voice quality problems don’t announce themselves through your tools. They announce themselves through your customers, by which point the damage is already done: the call failed, the frustration landed, and support has a ticket to chase down after the fact.
Reactive monitoring sets up a familiar loop. A customer calls in to report choppy audio or a dropped call. A ticket gets created. Someone starts pulling traces, hoping the relevant data is still there. If the customer calls back, you might have enough to triangulate the issue. If they don’t, you’re working from incomplete information on a problem that may already be recurring elsewhere on the network.
The technical gap here sits in how most monitoring tools handle RTP streams. Tools that track RTCP reports or rely on endpoint-generated statistics only get a picture of what devices chose to report, at the intervals they chose to report it. Network conditions that degrade gradually, or briefly but severely, often fall between those reporting intervals entirely.
Passive, inline monitoring of the actual RTP media stream changes the detection model. When probes analyze every packet in real-time and calculate quality metrics per timeslice across all active streams, quality degradation becomes visible as it develops, not after a user notices it. Transport quality indicators like jitter trends, packet interarrival irregularities, and burst loss patterns can trigger alarms well before they reach the threshold where speech becomes audibly impaired.
A sender jitter fault is a good example. When a device’s software can’t maintain a consistent packet rate, the resulting interarrival pattern is quite distinct. Automated detection flags it at the stream level, points to the affected calls, and identifies the likely source. Intelligent alarming is also a game changer in network operations. Support teams don’t wait for a complaint to know something’s wrong with a specific endpoint or network segment.
Getting ahead of quality issues also changes the customer support conversation. When first-line support has real-time access to call-level quality data, they can verify a complaint against actual measurements from the moment the call occurred, without waiting for second-line analysis. The resolution path gets shorter and the back-and-forth with the customer drops considerably.
Sign #4: Your Go-To Troubleshooting Tools Were Built for a Different Problem
Packet analyzers and open-source SIP monitoring tools earned their place in network engineering workflows, and for certain tasks they still earn it today. Wireshark is genuinely useful for inspecting individual packet captures. Homer does a reasonable job aggregating SIP signaling data and making it searchable. The issue is deploying them as the primary means of monitoring voice quality across a production network.
Wireshark works by capturing raw traffic at a specific point, at a specific moment. Getting useful data out of it requires someone to be looking in the right place at the right time, then manually working through packet traces to find the anomaly. On a large network carrying thousands of concurrent calls, that approach scales poorly. By the time a capture is running, the event that caused the problem may have already passed.
Homer sits closer to a proper monitoring system in architecture, but its visibility centers on SIP signaling. The RTP media layer, covering the actual audio packets, their timing, their sequence integrity, and their loss patterns, largely stays outside Homer’s scope. A network can generate clean SIP data in Homer while silently dropping audio mid-call on a portion of its traffic.
The cases where generic tools fall short tend to follow a pattern. Consider an enterprise network where users report one-way audio intermittently, with no obvious trigger. SIP traces look fine. A Wireshark capture on demand shows nothing unusual. The problem turns out to be zombie streams: RTP flows from previous calls that never terminated due to a bug in the IP-PBX. Those streams persist, and when a new call lands on the same destination IP and port, the receiver picks up the stale stream first and discards the new media entirely. Reproducing and capturing that scenario manually, at the right moment, on the right flow, is extremely difficult without continuous RTP monitoring across all active streams.
Generic tools also tend to focus on RTCP reports rather than the RTP stream directly. RTCP carries quality statistics reported by endpoints at periodic intervals, but endpoints report what they observe locally, and they do it infrequently. Impairments that develop between reporting cycles, or that originate upstream of the endpoint, don’t always show up accurately in RTCP data, assuming that RTCP is not blocked somewhere in the network.
A carrier-grade monitoring solution watches RTP continuously, across the full network, analyzing every packet as it moves through the infrastructure. That’s a fundamentally different model from pulling a capture when someone notices a problem.
Sign #5: Tracking Down the Root Cause of a Voice Problem Takes Your Best Engineer Half a Day
When a voice quality issue surfaces on a network without automated root cause analysis, the investigation process tends to follow a well-worn path. Someone with deep protocol knowledge pulls whatever data is available, works through call records manually, cross-references RTP stream data with signaling logs, and eventually narrows down the likely cause. On a complex network, that process can stretch across hours or, for intermittent problems, days.
The cost of that investigation sits in a few places at once. Engineer time is the obvious one. The less visible cost is the window between when a problem starts and when it gets resolved, during which every call traversing the affected network segment delivers a degraded experience.
Modern VoIP networks produce a volume of traffic that makes manual investigation increasingly impractical as the primary approach. A network carrying tens of thousands of concurrent calls generates a corresponding volume of RTP streams, each with its own quality characteristics, anomalies, and potential fault signatures. Asking engineers to sift through that manually puts a hard ceiling on how fast problems get found and fixed.
Automated root cause analysis works by recognizing that most network impairments leave distinctive patterns in RTP and SIP traffic. Sender jitter, for instance, produces a very specific signature in packet interarrival times: the sending device consistently dispatches packets too early or too late relative to the expected 20-millisecond interval, because its software can’t maintain a steady packet rate. A monitoring system trained to recognize that pattern identifies it automatically across all active streams, flags the affected calls, and points to the source.
Other fault patterns work similarly. Zombie streams, codec mismatches, TTL exhaustion on long international routes, and media gateway misconfigurations each leave traceable signatures in the data. Continuous monitoring that detects and classifies those patterns automatically transforms root cause analysis from a reactive investigation into a near-real-time notification.
The operational impact of getting that detection time down is significant enough that it warrants dedicated attention, and reducing mean time to repair by up to 80% covers the mechanics of how faster fault detection translates into measurable improvements in service quality management.
The engineers who previously spent hours chasing a fault signature through packet traces can focus on the problems that genuinely require deep expertise: novel failure modes, complex multi-carrier routing issues, and network architecture decisions. Automated detection handles the rest.
What a Modern Voice Monitoring Setup Actually Looks Like
The five signs covered above point to a common underlying gap: monitoring that captures too little of what a call actually does, too late to act on it meaningfully. Closing that gap means building full visibility across both the control and media planes simultaneously, with enough temporal resolution to catch problems as they develop rather than after users report them.
Dual visibility, the ability to correlate SIP signaling data and RTP media stream data at multiple points across the network, forms the foundation. SIP tells you the call was set up. RTP tells you what the call actually delivered. Correlating both, per call, across every network segment, produces a complete record rather than a partial one.
Layered on top of that is how quality data gets calculated and stored. Breaking each RTP stream into fixed 5-second intervals and computing quality metrics per segment, rather than averaging across the full call, produces quality data records with genuine diagnostic value. A sharp degradation at minute four shows up as a sharp degradation. A one-sided audio problem shows up in the stream where it actually occurred.
Automated root cause analysis then works against that granular data continuously, matching known impairment patterns to the streams where they appear, and surfacing faults before operations teams would otherwise know to look for them.
Taken together, those capabilities describe what a carrier-grade voice monitoring platform needs to cover. Qrystal was built around exactly this architecture, for networks ranging from enterprise deployments to large-scale international wholesale environments.
Where Do You Go From Here
The tools described in each sign above worked well enough at the scale and complexity of networks a decade ago. Today’s networks, with their cloud deployments, multi-carrier routing, and growing call volumes, surface problems those tools weren’t designed to find.
The monitoring methods that match today’s infrastructure exist and are already running on production networks. The question worth asking is whether yours is one of them.