
Introduction
Many new opportunities arise when applying artificial intelligence and machine learning (AI/ML) technology to telecommunications. Problems like churn prediction or fraud detection that have been difficult to pinpoint can now be addressed using very powerful techniques. This post looks at AI/ML in telecommunication, focusing on the particularities in telco data. However, setting up an AI/ML model involves other aspects as well e.g., using the right tools and services. This post is by no means a comprehensive list of all aspects but rather the start of an informative discussion.
The need for reliable data
Machine learning uses features (a set of variables) to find generalizable patterns in the data. Hence, the reliability of the model depends on the quality of the applied features. Inconsistencies in the data due to incorrect data tracking or management (e.g., feature storing) may lead to mistakes in prediction. Qrystal, Voipfuture’s VoIP monitoring and analytics solution, continuously gathers signalling and media data on all live calls. To handle the enormous amount of information contained in RTP media packets, Qrystal Probes create summary records for every 5 second segment of an RTP stream. These fixed time slices enable a precise examination of signal quality over time, which leads to an accurate representation of the voice service.
Imagine a call of one hour with 500 packet losses. If these packet losses are equally distributed throughout the call, one would not notice any degradation in the voice quality. However, if the packet losses are accumulated in two specific minutes the call experience would be quite severely impacted. Qrystal differentiates between these scenarios. For each fixed time slice, Qrystal Probes record a rich variety of data, including burst losses, packet interarrival time, or codec information. This data richness enables comprehensive data analyses with immense data reliability since no external sources are used. However, having reliable and precise data is only one important aspect when setting up an AI/ML model.
Data requirements for different types of learning
AI/ML algorithms can be divided into three classes:
- supervised learning,
- unsupervised learning
- and semi-supervised learning.
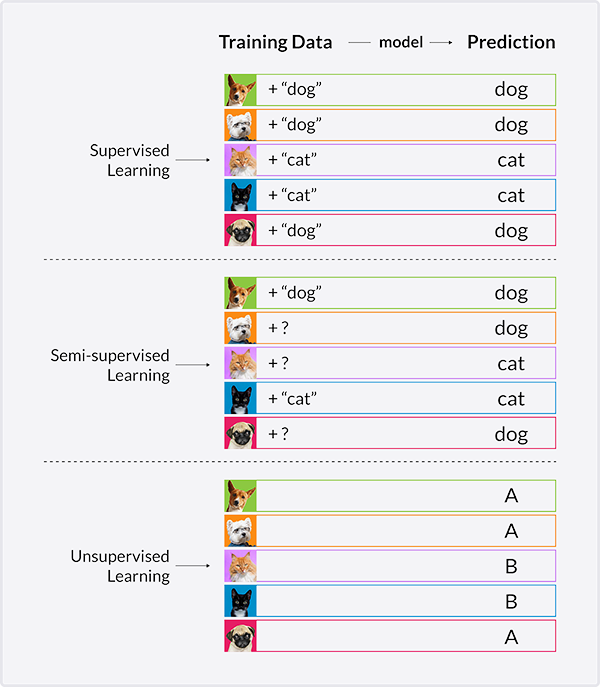
In unsupervised learning, cases are divided into previously unknown groups based on their feature characteristics. A supervised learning paradigm uses the features to predict a provided dependent variable and a semi-supervised learning paradigm basically combines the two.
In telecommunications, we are often interested in solving problems using a supervised learning algorithm. Fraud, churn prediction, and alarm classification are typically specific cases where the dependent variable can be provided. However, in all examples gathering reliable dependent variables is effortful and can be troublesome because it involves a high degree of investigative work, including the assessment of sensitive business data. Hence, getting a reliable dependent variable, e.g. “fraud” or “not fraud”, is not trivial.
To clarify, a very common use case for supervised learning is the recognition of animals in pictures. Here the dependent variable is the observed animal (cat, dog, horse) – a dependent variable that is easily created. In contrast, for classifying alarms in the telco domain one needs to understand
- how a specific metric can fluctuate,
- what fluctuations are outside normal boundaries,
- whether these fluctuations have a business impact and
- if this impact is large enough to justify an investigation.
Furthermore, different forms of alarms can be triggered and so forth.
Hence, establishing a correct dependent variable involves the cooperation between different professionals, assessing the problem from different angles (technical perspective, management perspective, customer perspective, etc). This is a task that requires a lot of effort and trust.
If only a small part of the cases in a dataset has a corresponding dependent variable a semi-supervised learning paradigm could be used. Pseudo-labeling techniques could then be applied to create a dependent variable for the rest of the data. However, pseudo-labeling can create more unwanted variability in the data, which decreases prediction accuracy.
Unsupervised learning can be used, if a dependent variable cannot be generated or if it is of interest to explore unknown cases/groups in the data. Unsupervised learning is often used for customer segmentation to understand customer behavior and tailor marketing strategies. Furthermore, anomaly detection, where outliers in the data are highlighted, can be applied to alarming, as well. However, the result of an unsupervised learning paradigm needs to be assessed and interpreted by an analyst. Hence, post-model processing work is continuously required, which is often not feasible in an everyday business situation.
The downside of Five-Nines – Unbalanced data
For almost a century communication service providers have taken great pride in five-nines availability, i.e. that the voice service is available 99.999% of the time in a given period. This high availability in general means that any type of “interesting event” is typically very rare. This leads to the situation that data in the telco domain is often unbalanced, meaning that cases of interest, e.g. ‘fraudulent call’, are very few and the majority of cases are considered ‘normal’.
This could be seen as an argument in favor of using an unsupervised algorithm to find the outliers. However, as noted above supervised learning paradigms are more relevant in telecommunication due to the questions of interest and the applicability of the results.
Here, one can solve the problem of unbalanced data by applying several techniques
- data filtering,
- data weighting
- and data augmentation.
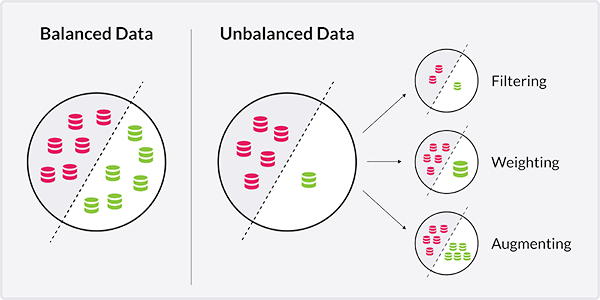
Data filtering needs to be appropriate for the use case and is not allowed to bias the data. For example, when the main aim is to discern cats and dogs one can exclude other animals from the picture pool. Secondly, one can assign weights to the outcome variables during training. In simple words, these weights tell the model to put a higher emphasis on a certain category. If one outcome variable (e.g., dogs) is grossly underrepresented in the data it makes sense to add a higher weight to this category not to ignore it. Lastly, data augmentation can be used to create a more balanced dataset. For example, one can artificially increase the number of dogs in the dataset by using the same pictures but applying slight changes to them.
The importance of time in telco data
The last topic addressed here is the importance of time in telecommunication data. Alarms, minute volumes, and fraud can have different signatures depending on the time of day, day of week and day of the year. For example, at Voipfuture we have predicted when the customer of a wholesale carrier would show a decrease in minute volume to a certain destination. We compared the predictive power of a neural network, which is not sensitive to developments in time, with the predictive power of a recurrent neural network, which is very sensitive to changes over time.
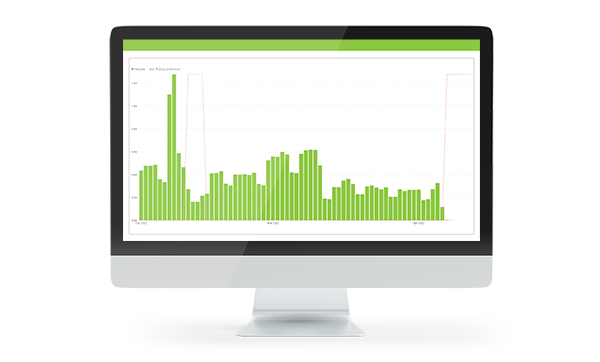
Even when including features with some temporal information in both models the recurrent neural network outperformed the simple neural network by far. That is, the simple neural network was not predicting days with substantial minute losses better than chance, whereas the recurrent neural network performed with an accuracy of approximately 99 %. Hence, the recurrent neural network helped to reveal how much profit would be lost, if unwanted fluctuations in minute volumes were not addressed.
Conclusion
AI/ML techniques have many applications in telecommunications and can for example help to detect fraud and anomalies, support root cause analysis, and automate service management.
But applying AI/ML to the telco domain also brings about its challenges. Here we gave a glimpse into some of these challenges and possible solutions to encourage an open informative discussion so that AI/ML becomes a usable tool rather than a fancy wish. This post is the beginning of a series on AI/ML in telecommunications and will be followed up by posts describing specific examples and the usage of AWS cloud services when setting up a model. The general aim is to create transparency and a mutual understanding of the topics.
