
Air traffic control is one of those domains where ‘digital transformation’ isn’t a buzzword; it’s a necessity. The shift from legacy circuit-switched systems to IP-based voice communications has been underway for over a decade, and it continues to reshape how Air Navigation Service Providers (ANSPs) operate. The benefits are real: better scalability, reduced costs, enhanced flexibility. But so are the risks.
ATC voice communication simply cannot afford impairments. A dropped word, a misrouted call, a second of silence at the wrong moment – the consequences are too high. That’s why IP migration in ATC demands not just good planning, but rigorous, continuous monitoring.
This article walks through the compelling reasons to embrace IP in ATC, explains what needs to be monitored and why, and then gets into the real substance: four case studies drawn from actual ATC deployments. Each one illustrates a different type of problem and how the right monitoring tools made the difference.
Why IP Makes Sense for ATC, and Why It’s Still Challenging
The case for IP in air traffic control comes down to five core advantages:
- Safety through better situational awareness. VoIP enables simultaneous ground-to-ground and air-to-ground communications through a single, integrated platform. Controllers get a clearer, more complete picture of what’s happening, reducing miscommunication and improving decision-making.
- Operational efficiency. IP interoperability lets controllers manage multiple VoIP radio systems from a single workstation, reducing complexity and switching time.
- Cost savings. IP infrastructure scales on demand. You can add capacity without overhauling physical hardware, making it far more economical than traditional circuit-based systems.
- Flexible, distributed operations. Geographic barriers no longer limit ATC collaboration. Air Traffic Control Officers can coordinate across distances, share load between control centers, and support remote tower and virtual center concepts.
- Built-in resilience. The layered architecture of IP networks provides redundancy at multiple levels, improving overall service availability compared to single-path legacy systems.
That said, none of these benefits materialize automatically. Moving to IP introduces a new class of problems, most of them subtle, intermittent, and difficult to detect without purpose-built monitoring tools. Unlike traditional telephony, IP-based voice is susceptible to packet loss, jitter, delay, and codec mismatches, all of which can degrade or completely disrupt communications.
What You Need to Monitor in an IP-Based ATC Environment
Once you’ve made the move to IP, or while you’re in the process, ongoing monitoring is non-negotiable. These are the key areas to watch:
- Call quality: both ground-to-ground and air-to-ground calls
- Network performance: packet loss, jitter, delay, and standards conformance of individual network elements
- User experience (MOS): Mean Opinion Score of live calls, including simultaneous transmissions
- Radio signal health: squelch power, noise floor, anomalies, and interference patterns
- ATC efficiency metrics: frequency utilization and squelch durations
- Regulatory compliance: standards like EUROCAE ED-136 set specific thresholds for MOS, user experience, and delay that your network must consistently meet
With that framework in mind, let’s look at what real-world deployments actually look like when things go wrong, and what it takes to catch and fix them.
Four Case Studies from Real ATC Deployments
Case 1: The Calls Nobody Knew Were Happening
This case sounds almost too simple to matter — until you think about what it implies.
A Voice Communication System (VCS) repeatedly attempted to connect to a radio unit, sending a call every 5 seconds. Each attempt was met with the same response: a SIP “603 Decline”, meaning the radio refused the connection. The calls went unanswered, no audio was exchanged, and the whole exchange seemed harmless enough on the surface.
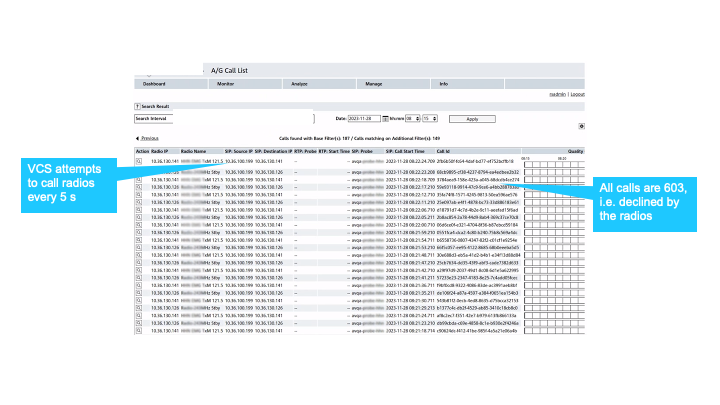
The catch? The ANSP had no idea this was happening. The source turned out to be an active testing system, but the fact that constant, automated call activity was occurring on the network without anyone’s knowledge was the real concern.
This case highlights a fundamental issue: without network visibility tools, you simply don’t know what’s running on your own infrastructure. Blind spots like this can be benign or mask something far more serious. The only way to tell the difference is with proactive, real-time monitoring.
Case 2: Poor Voice Quality. But Whose Fault Is It?
MOS (Mean Opinion Score) is the industry-standard metric for voice quality. EUROCAE document ED-136, which governs ATC voice communications, sets the bar: a MOS below 4.0 is unacceptable. In this case, MOS levels were repeatedly dropping into the yellow and red zones, indicating a significant, recurring quality problem.
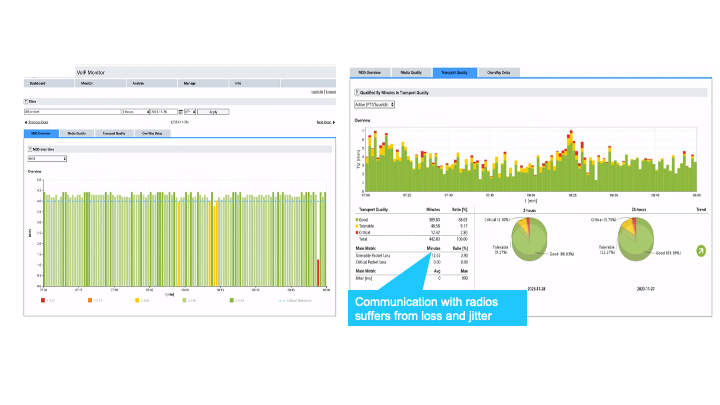
What made this case tricky was identifying the source of the problem. Low MOS doesn’t tell you who’s responsible; it just tells you something is wrong. The ANSP’s first instinct might be to look inward at its own systems, but the monitoring data pointed elsewhere.
A deeper network analysis revealed 3% packet loss on the link between the radio site and the central site, a level that’s completely unacceptable in a managed, paid-for network. That loss was being introduced by the network provider, not the ANSP’s own equipment.
Armed with this evidence, the ANSP had the data they needed to escalate directly to the provider and demand remediation. Two lessons stand out here: continuous MOS monitoring of actual live calls is essential for ED-136 compliance, and you can’t fix what you can’t see.
Case 3: Complete Silence on a Critical Call
Imagine a controller picking up a coordination call with a colleague at a neighboring airport, and hearing nothing. Not static. Not degraded audio. Just silence.
This is one-way audio, and in ATC, it’s as bad as it gets.
The root cause was a codec mismatch. During call setup, the two systems negotiated which codec to use, the digital encoding format for converting voice to data, and back. The ANSP’s system offered two options: G.711 A-law and G.711 µ-law (mu-law). The airport’s system selected µ-law as the agreed format. But then, the transmitted audio is in A-law.
The result: the receiving side expected one encoding format, received another, and couldn’t decode the audio stream. Total silence.
In this case, having a tool that could identify the codec mismatch immediately enables a swift fix before the issue has time to escalate. The broader lesson: codec negotiation is a common failure point in multi-vendor VoIP environments, and it’s exactly the kind of subtle, below-the-surface problem that only a dedicated monitoring system will catch in real time.
Case 4: When Network Equipment Breaks Its Own Rules
This one is a reminder that even your vendor-supplied, certified infrastructure can quietly violate the standards it’s supposed to follow.
An ANSP’s operations team noticed that their passive monitoring tool was reporting an estimated MOS (eMOS) of 1.0 during idle periods on certain air-ground links. That’s the floor; it can’t get worse. The unusual thing: when actual voice calls were taking place, the quality was fine. The problem only appeared when nothing was being said.
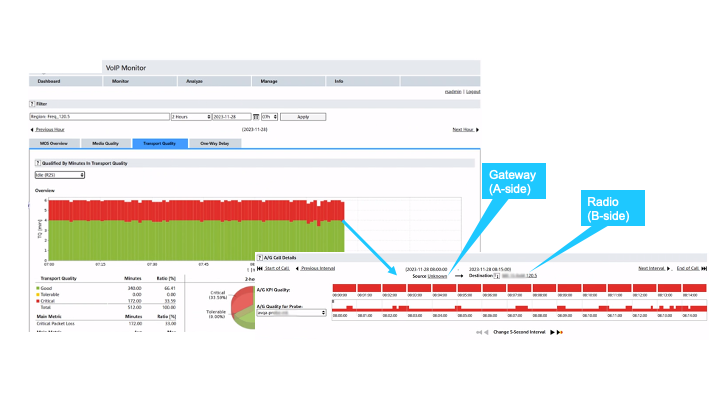
Digging into the data revealed that approximately 90% of packets were being lost in one direction, from a gateway outward. The reverse path, from radios back to the gateway, was clean. So why was only one direction, only during idle periods, showing such massive loss?
The answer was a standards violation. In RTP (Real-time Transport Protocol), every packet carries a sequence number that increments by one with each packet sent. A mechanism defined in IETF RFC 3550 and EUROCAE ED-137. This allows receivers to detect missing packets by identifying gaps in the sequence.
The gateway in question was incrementing its sequence number by an average of 10 per packet during idle periods, not by 1. So, from the receiver’s perspective, every packet appeared to have 9 missing predecessors. The result: a reported packet loss rate of around 90%, even though the packets arrived intact.
In this case, the radios handled the malformed RTP stream gracefully, but that’s not guaranteed. Relying on receiving equipment to compensate for a standards-violating transmitter is not a safety strategy. The takeaway: the conformance of every network element to standards needs to be actively monitored, not assumed.
IP Migration Is Worth It, But Only If You Monitor What You Can’t See
The aviation industry is at an inflection point. Virtual centers, digital remote towers, and cross-border ATC operations all depend on rock-solid IP infrastructure. Migrating to IP-based systems is no longer optional; it’s the foundation of modern air traffic management.
But as these four cases show, IP migration doesn’t end at go-live. Problems emerge during migration and keep emerging in normal operations. From third-party network providers, from interconnection partners, from your own radio infrastructure, and, yes, from equipment that’s supposed to be standards-compliant but isn’t.
When something goes wrong, you need to answer four questions fast: what happened, when, where, and why. That requires 24/7 monitoring of live traffic across every layer of your network. The benefits of IP in ATC are real and substantial. So are the risks. The difference between realizing those benefits and being caught off-guard by those risks comes down to one thing: knowing what’s happening on your network, all the time.