
Picture this: You’re about to make an important call, maybe to a friend, maybe to seal a deal. Either way, you expect nothing but top-notch voice quality every single time you dial. After all, who wants to deal with dropped calls or fuzzy connections?
For service providers, delivering this kind of consistent, crystal-clear experience is like walking a tightrope. You’re constantly juggling different challenges, from getting the right data to actually understanding what it means. Think about it: if they can’t see the full picture, how can they fix what’s broken?
And it’s not just about pinpointing the problem; it’s about doing it fast. Nobody wants to wait around while their call drops or turns into a one-way street. Plus, when something goes wrong, it’s usually the provider who gets the blame—even if it’s not their fault!
An additional kicker: with so many providers out there, customers aren’t afraid to jump ship if they’re not happy. So, how do you, as a provider, stay ahead of the game?
Well, it all comes down to having the right tools – strong monitoring technology that can dig deep into the nitty-gritty of call traffic, separating the signal from the noise. This tech should be like the canary in the coal mine, pointing out problems before they become full-blown disasters
And it’s not just about spotting issues; it’s about fixing them, too. That means having analytics and reporting features that actually make sense—no more sifting through mountains of data just to find a tiny clue.
So, yeah, maintaining top-notch voice quality might be tough, but with advanced technology tools and methodologies, you can handle anything that comes your way. Take, for instance, the way we usually look at call data. When you stick to conventional averaging per call, you’re basically missing out on a ton of useful info.
What you really need is to dive into each RTP stream in real-time and break it down into bite-sized chunks, like 5-second segments. That way, you can really get a feel for how voice quality changes over time as packets travel across your IP networks.
By going down this path, you’re not just catching problems as they happen; you’re nipping them in the bud. You can spot issues right when they pop up, figure out what’s causing them, and—for a change—actually do something about it. Plus, you’ll have all the data you need to compare and aggregate service quality info. It’s like having a roadmap to better voice quality, all neatly laid out in front of you.
Let’s further explore this path.
The Elements that Define Service Quality Monitoring
When it comes to IP services, Voice over IP (VoIP) stands out as one of the trickiest to nail down. Think about it: you’re talking real-time and interactive communication here. You need those RTP media streams to be smooth as silk—no delays, no jitters, and definitely no dropped packets. It’s the difference between a seamless chat and a frustrating game of broken telephone.
And you know what’s key to making sure those calls go off without a hitch? A rock-solid IP network. That’s where the first element of network performance monitoring comes into play. You need visibility to all the nitty-gritty details: from jitter and packet interarrival times to packet loss and round-trip delays. It’s like having a backstage pass to the inner workings of your network.
But it doesn’t stop there. You also want to keep an eye on things like network and service policies, as well as the conformance of end devices and other network elements. Because let’s face it, when it comes to keeping your users happy, every little detail counts.
By keeping tabs on these network performance metrics, you’re not just ensuring smooth sailing today—you’re future-proofing your network for whatever comes next. It’s like having a crystal ball that tells you exactly what your network needs to stay ahead of the game.
The next element is the ability to perform root cause analysis of VoIP service degradations, which can be extremely time-consuming. Digging into the root cause of VoIP service hiccups – trust me – it’s a time-sucking monster. Without the right data, teams are left floundering, trying to guess what’s causing the issues. They resort to deploying recording tools and relying on customer feedback to piece the puzzle together.
A midpoint monitoring approach can significantly speed up the troubleshooting process. Imagine having monitoring points strategically placed throughout your network, meticulously tracking stream quality, call signals, and registrations. Spotting trouble? No problem. Just sift through the data from different segments, and you’ve zeroed in on the issue in no time.
But wait, there’s more. Enter automatic root cause indicators. They are constantly scanning SIP and RTP traffic, identifying those troublesome impairment patterns. They flag calls and streams affected by these issues, streamlining the troubleshooting process.
Take sender jitter, for instance. It’s like a signature left behind by the RTP sender’s device, disrupting packet timing and causing chaos. Fortunately, in-call measurements detect this anomaly, helping teams swiftly diagnose the problem.
Now, let’s talk about the third element: customer support. It’s the beating heart of excellent service quality, no doubt about it. Success here is all about tackling customers’ needs head-on, right from the get-go. But…first-line support needs the goods, the juicy details to really get the job done. Unfortunately, that kind of info isn’t always easily available.
So, what’s the usual drill?
Step one: The customer calls in with a gripe, and a ticket is created.
Step two: start tracing those calls, hoping for a eureka moment.
Step three: wait for the customer to ring back (fingers crossed).
Step four: Finally, use that trace to crack the case.
Rinse and repeat until the problem’s sorted. Not exactly the most efficient way to tackle things, right?
But imagine having this: real-time call-related info at your fingertips. Your customer care agents could immediately jump on it, verifying complaints in a flash. And if the issue checks out, they’ve got all the evidence ready to roll, neatly attached to that ticket for second-line support.
Proactive operations are at the top of every CSP’s to-do list. But most network operators and carriers are still playing the waiting game, relying on customers to sound the alarm when something’s amiss. It’s like saving on smoke detectors and relying on your neighbors to call the firefighters.
How about if you had an alarming mechanism for existing or imminent quality hiccups in near real-time and with endless triggers? You could even handle degrading network performance way before customers even notice a blip. How? By setting alarms on transport quality indicators that kick in well before they’re even audible. Talk about getting ahead of the curve! This proactive approach saves valuable time and resources, letting you tackle issues before they spiral out of control.
Nice-To-Have or a Lifesaver?
All-IP network architectures rely on the Real-time Transport Protocol (RTP) as the core technology for real-time communication services. RTP is used for the media transport of services such as voice and video. Once a voice call kicks off, speech is sliced into RTP packets and shuttled across the network until the chat wraps up. Any hiccups in this packet flow can spell disaster for voice quality, leading to choppy speech and dropped words. In short, top-notch connections demand a steady stream of RTP packets.
But let’s get real: in the wild world of IP networks, this packet flow is often subject to all sorts of disruptions, courtesy of dynamic network conditions, equipment quirks, and fluctuating traffic loads. And let’s not forget, RTP packets share the line with a slew of other data and communication services—it’s the nature of all-IP networks, isn’t it?
You’d think all the mechanisms for managing this traffic would be in place, but alas, the challenge of maintaining crystal-clear voice quality in all-IP networks persists.
Sure, there are technologies promising to deliver Quality of Service (QoS), but do they actually deliver the goods? Spoiler alert: not always. Your network might not be the only culprit—your suppliers’ and customers’ environments could be responsible too. That’s where monitoring comes into play. But here’s the rub: traditional voice quality monitoring can be a real headache, especially when it’s just confirming what you already know. It’s like going to the doctor when you’re sick—you don’t need them to tell you that. You want answers and solutions.
Only innovative RTP monitoring solutions provide the diagnostics to assess quality, to localize the root causes of impairments and consequently to improve voice quality and overall network performance. The RTP media flow is continuously analyzed in real-time to diagnose issues such as limited bandwidth or improperly functioning network components. In such cases, voice quality is affected by drop-outs. Equally hard to identify are typical impairments from underperforming or misconfigured end devices. For instance, poor software implementations may be eating up your available delay budgets. When needed, such safety margins are no longer available to your network.
Whatever the reason for bad voice quality is, the service provider’s network is considered to be responsible. Precise measurements to evaluate your suppliers’ and interconnection partners’ performance are essential to guarantee agreed service levels to your customers. It’s all part of the voice monitoring revolution.
Achieving a True End-to-End Monitoring – Easier Said Than Done?
Ensuring seamless voice quality in VoIP calls across varied networks and network elements is no small feat. With numerous potential sources of issues, maintaining consistent in-call service quality demands vigilant monitoring of all RTP media streams, from start to finish. This is where our unique RTP time slicing technology comes into play. By analyzing media streams in 5-second intervals, we generate quality data records (QDRs) packed with condensed measurements for each RTP stream segment. These QDRs contain a wealth of values, ratios, KPIs, and indicators, facilitating effective root cause analysis by automatically pinpointing impaired segments.
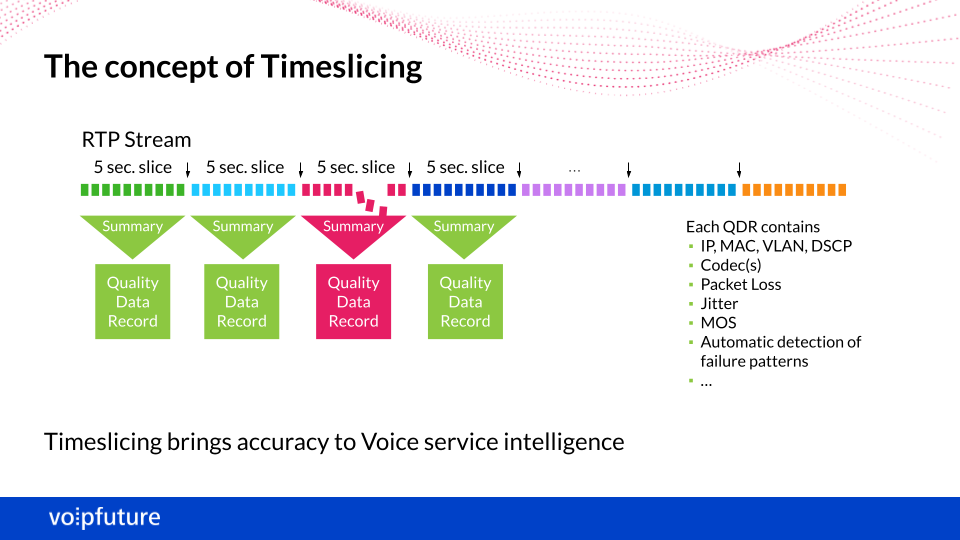
Our pattern-matching technology, operating in real-time, ensures that no detail goes unnoticed. Unlike conventional metrics relying on average values per call, our detailed QDRs empower you to swiftly identify when and where impairments occur, streamlining troubleshooting and elevating service quality management to new heights.
Qrystal employs a dual-visibility mechanism to consolidate data on both media and control plane traffic measured at various network points. To start with, Qrystal Probes utilize a patented online correlation mechanism to link signaling and media information during active VoIP sessions. This mechanism adeptly identifies and characterizes media streams throughout the session lifecycle, including early media stages and instances of in-call codec changes. Furthermore, it recognizes and correlates media streams altered on the IP layer to traverse firewalls and Network Address Translators (NAT), ensuring comprehensive coverage.
In the subsequent stage, the Qrystal Manager harmonizes all data records and streams associated with a call, creating comprehensive call detail records (CDRs) representing an end-to-end view. By analyzing attributes such as SSRCs, start times, and endpoint IP addresses, Qrystal discerns which streams and data records pertain to the same call, facilitating holistic analysis.
The quality of a call’s media is gauged based on the lowest quality stream along the call path. Any disparities among metrics across streams or data records are promptly flagged by Qrystal to facilitate detailed analysis.
For the control plane, the end-to-end view is created by Qrystal’s call detail records. The data of all call legs are correlated to a CDR, which only contains the most relevant information collected close to the endpoints.
Let’s Wrap It Up
If there’s only one thing to take from this article it is that ensuring top-notch voice service quality in the world of IP networks is a multifaceted challenge. From maintaining crystal-clear communication to swiftly diagnosing and resolving issues, advanced monitoring technology is essential. By investigating the nitty-gritty of call traffic, separating signal from noise, and leveraging real-time analysis, you can proactively address problems before they escalate. Additionally, achieving true end-to-end monitoring, encompassing both media transport and signaling, requires innovative approaches like RTP time slicing technology and comprehensive call detail records. These tools empower you to not only identify impairments but also localize root causes and optimize network performance, ultimately delivering a seamless user experience.
